چرا ۹۰٪ پروژههای هوش مصنوعی صنعتی شکست میخورند؟
نقشه راه ۴ فازی مدیران برای ساخت یک “AI پایدار” در کارخانه
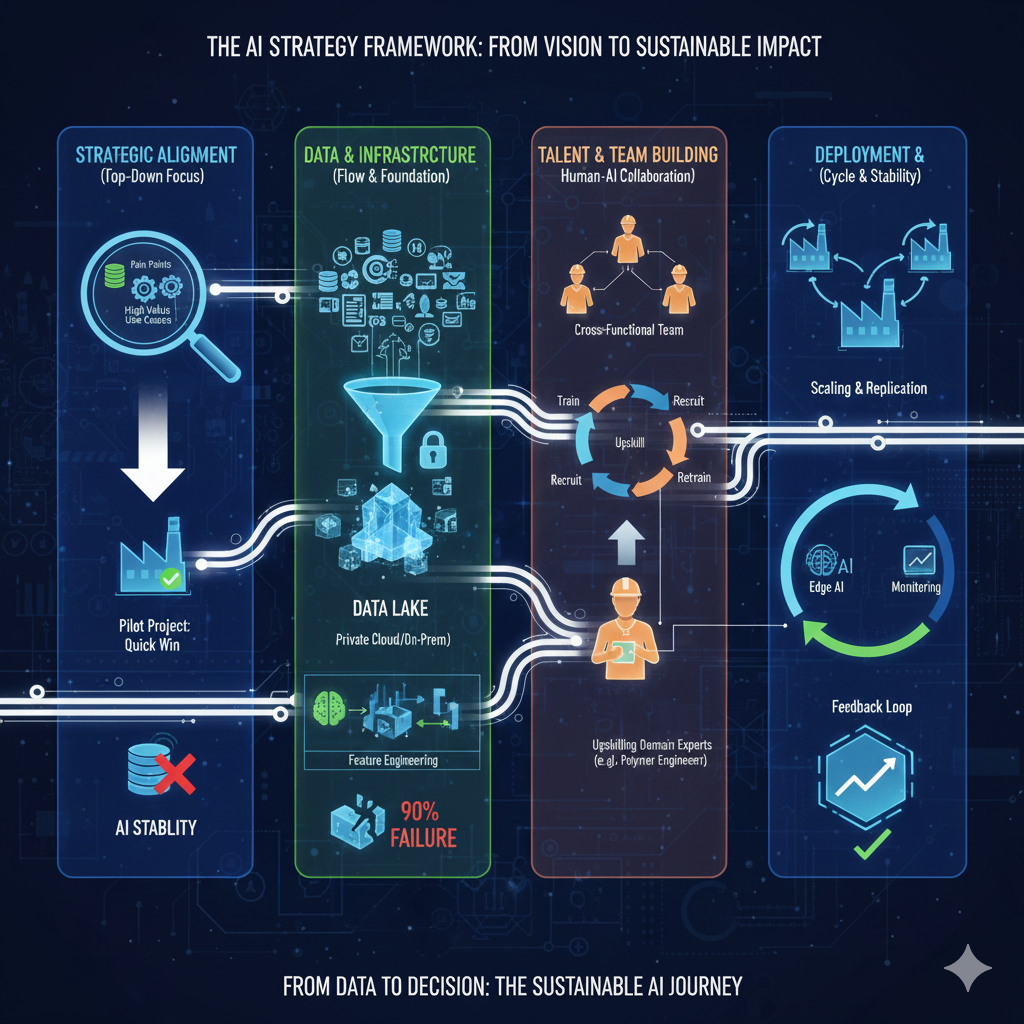
پیادهسازی موفق هوش مصنوعی (AI) در محیطهای صنعتی، فراتر از یک تصمیم تکنولوژیک ساده است. طبق آمار، درصد قابل توجهی از پروژههای AI در فاز آزمایشی (Pilot) باقی میمانند یا پس از استقرار، به دلیل عدم توانایی در حفظ دقت، شکست میخورند. مشکل صرفاً فنی نیست؛ بلکه استراتژی هوش مصنوعی سازمان، چالش اصلی و عامل تعیینکننده است که یک تحول سازمانی و دادهمحور را میطلبد.
شرکتهایی که توانستهاند AI را از یک هزینه تحقیقاتی به یک دارایی صنعتی و مزیت رقابتی پایدار تبدیل کنند، از یک نقشه راه چهار مرحلهای هوشمندانه پیروی میکنند که هم ابعاد فنی و هم ابعاد مدیریتی را در بر میگیرد.
۱. فاز تعریف و همسوسازی استراتژیک: چرا AI؟
بیشترین شکستها در پروژههای AI از آنجا ناشی میشود که سازمانها به دنبال تکنولوژی هستند، نه به دنبال حل یک مسئلهی ارزشمند. موفقیت با تعریف یک فرضیه (Hypothesis) کسبوکاری محکم آغاز میشود.
الف. تمرکز بر ارزش افزوده و نه صرفاً تکنولوژی
-
تشخیص مسئله با ارزش بالا: قبل از نوشتن اولین خط کد، تیم رهبری باید شناسایی کند که کدام چالشهای عملیاتی یا استراتژیک، بیشترین بار مالی را بر دوش شرکت میگذارند. مثلاً، در یک کارخانه تولید پلیمر، مسئله اصلی ممکن است نوسانات بالای کیفیت محصول نهایی (Quality Variability) یا هزینههای نگهداری غیرمنتظره تجهیزات باشد. هدف باید مشخص باشد: “به کارگیری AI برای کاهش ۲۵٪ نوسانات MFI (شاخص جریان مذاب) در راکتور پلیمریزاسیون.”
-
رویکرد تدریجی و آزمایشی (Pilot Projects): شروع با پروژههای آزمایشی کوچک (Quick Wins) و کمریسک یک استراتژی حیاتی است. این پروژهها (با زمان اجرای حداکثر ۶ ماه) به سازمان کمک میکنند تا سریعاً ارزش اولیه (ROI) را مشاهده کند و اعتماد مدیران ارشد و اپراتورهای خط تولید را جلب نماید. شکستهای کوچک در این مرحله، درسهایی را برای پروژههای بزرگتر فراهم میکنند و نشان میدهند که آیا زیرساخت دادهای شما برای مدلهای پیچیدهتر آماده است یا خیر.
-
همسویی با استراتژی کلان: هر پروژه AI باید مستقیماً با یکی از اهداف کلان شرکت (مانند افزایش حاشیه سود، پایداری مواد، یا تسریع ورود به بازار) همسو باشد. پروژههایی که تنها در آزمایشگاههای تحقیق و توسعه باقی میمانند و ارتباطی با خط مقدم کسبوکار ندارند، عموماً در فاز استقرار شکست میخورند.
ب. مدیریت ریسکهای اولیه و تغییرات سازمانی
-
ریسک سرمایهگذاری و پیچیدگی مدل: در ابتدا، بهتر است مدلهای سادهتر و سریعالاجرا (مانند رگرسیون یا دستهبندی ساده) استفاده شوند. از توسعه شبکههای عصبی عمیق که هم دادههای زیادی نیاز دارند و هم زمان پیادهسازی طولانی، در فازهای اولیه باید پرهیز کرد تا شکستهای احتمالی، سازمان را دلسرد نکند.
-
شناسایی ذینفعان (Stakeholders): مشارکت فعال اپراتورهای خط تولید، مهندسان فرآیند و مدیران مالی از همان ابتدا، برای اطمینان از پذیرش مدل (Adoption) در مرحله نهایی، ضروری است. مقاومت در برابر تغییرات (Organizational Resistance) یکی از بزرگترین موانع غیرفنی است که باید از طریق شفافیت و آموزش مرتفع شود.
۲. فاز دادهمحوری و زیرساخت: مدیریت داراییهای دادهای و زیرساخت انتقال
موتور هوش مصنوعی بدون سوخت باکیفیت کار نمیکند و این موضوع، نقطه شکست بسیاری از سازمانها است. موفقیت داخلی AI، وابسته به تبدیل دادههای خام به داراییهای قابل استفاده (Actionable Assets) و زیرساخت انتقال امن آنها است.
الف. معماری داده و یکپارچهسازی
-
یکپارچهسازی منابع داده: دادههای صنعتی اغلب از منابع پراکنده و ناهمگون میآیند: سنسورهای خط تولید، سیستمهای ERP، گزارشهای LIMS و بازخورد مشتریان. استراتژی موفق، این است که تمام این دادهها از طریق یک پایپلاین داده (Data Pipeline) قوی به یک مخزن مرکزی مانند Data Lake منتقل شوند. این کار اساس یکپارچهسازی ۳۶۰ درجهای فرآیند را فراهم میکند.
-
تأمین زیرساخت انتقال داده از راه دور: برای شرکتهایی که خدمات پس از فروش هوشمند یا نگهداری پیشبینانه ارائه میدهند، زیرساخت ارتباطی امن و پایدار برای جمعآوری دادهها از سایتهای مشتری (محل استقرار ماشینآلات) حیاتی است. استفاده از راهکارهای شبکههای خصوصی صنعتی (Industrial Private Networks) و پروتکلهای امن، تضمین میکند که دادههای Real-time با امنیت بالا و کمترین تأخیر به Data Lake مرکزی منتقل شوند. این بستر، پلی است که فاز تولید (پایین منحنی) را به فاز خدمات (راست منحنی) متصل میکند.
-
بومیسازی و حاکمیت داده: بسیاری از سازمانها به دلایل امنیتی، حفظ مالکیت فکری و مقررات صنعتی، زیرساختهای ابری یا پلتفرمهای MLOps خود را در محیط داخلی سازمان (On-Premises) یا بر روی یک ابر خصوصی (Private Cloud) پیادهسازی میکنند.
ب. ملاحظات فنی داده
-
مهندسی ویژگی (Feature Engineering): دانشمند داده داخلی باید با همکاری متخصصان فرآیند، ویژگیهای هوشمند و مصنوعی (Synthetic Features) بسازد که فیزیک فرآیند را برای مدل ترجمه کند؛ مثلاً، محاسبه نرخ تغییر دما در ۲۰ ثانیه اول به جای صرفاً استفاده از مقدار دمای فعلی، یا محاسبه ضریب اصطکاک داخلی بر اساس دادههای گشتاور و سرعت. این لایه ارزش افزوده، تمایز اصلی یک پروژه موفق است.
-
مقابله با سوگیری داده (Data Bias): دادههای تاریخی معمولاً سوگیری دارند (مثلاً همیشه یک قطعه خاص خراب میشده است). تیم باید استراتژیهایی را برای مقابله با این سوگیریها (مانند نمونهبرداری بیش از حد یا استفاده از دادههای مصنوعی) در نظر بگیرد تا مدلها تصمیمات تبعیضآمیز یا غیرمؤثر نگیرند.
۳. فاز مهارت و ساخت تیم: پرورش متخصصان دامنه
تلاش برای استخدام یک تیم کامل از متخصصان خارجی پرهزینه است و اغلب منجر به شکاف بین دانش نظری AI و دانش عملی صنعت میشود. این شکاف، علت اصلی شکستهای AI در صنایع سنگین است.
الف. پرورش استعدادهای داخلی (Upskilling)
-
سرمایهگذاری روی مهندسان موجود: استراتژی موفق، تمرکز بر آموزش مجدد (Reskilling) متخصصان فعلی است. یک مهندس پلیمر که زبان پایتون و اصول یادگیری ماشین را میآموزد، ارزش بسیار بیشتری از یک دانشمند دادهی عمومی دارد. او هم مدل را میسازد و هم میداند که خروجی مدل چگونه روی اکسترودر یا راکتور اعمال میشود. این رویکرد، دانش دامنه (Domain Knowledge) حیاتی را حفظ میکند و مهندس را از پایین منحنی لبخند (تولید محوری) به سمت قلههای ارزش (نوآوری و مشاوره) سوق میدهد.
-
جذب مهارتهای کلیدی: سازمانها همچنان باید متخصصانی را در نقشهای حیاتی مانند معمار داده (Data Architect) و مهندس MLOps استخدام کنند که مسئول طراحی پایپلاینهای دادهای و زیرساختهای استقرار مدل هستند.
ب. نهادینه کردن MLOps و همافزایی تیم
-
تشکیل تیمهای چندرشتهای (Cross-Functional Teams): پروژهها باید توسط تیمی متشکل از حداقل سه نقش کلیدی تشکیل شوند: ۱. متخصص دامنه (Domain Expert): (مثلاً مهندس فرآیند) برای تعریف مسئله و مهندسی ویژگی. ۲. دانشمند داده: برای ساخت و آموزش مدل. ۳. مهندس MLOps/IT: برای استقرار و نگهداری مدل در محیط عملیاتی.
-
پیادهسازی MLOps: مدلهای AI صنعتی برخلاف نرمافزارهای سنتی، نیاز به نگهداری مداوم دارند. سازمانها باید ابزارهای MLOps (عملیات یادگیری ماشین) را پیادهسازی کنند تا چرخه عمر مدل (توسعه، تست، استقرار، مانیتورینگ و بازآموزی) به صورت خودکار مدیریت شود.
۴. فاز پیادهسازی و مقیاسپذیری: ساخت AI پایدار و خلق خدمات جدید
ارزش واقعی پروژه AI زمانی ایجاد میشود که مدل، به یک سیستم تصمیمگیری فعال در خط تولید تبدیل شود و خدمات جدیدی را خلق کند.
الف. استقرار هوشمند و Real-time
-
-
استقرار بر لبه (Edge Deployment): در بسیاری از فرآیندهای صنعتی (به ویژه کنترل فرآیندهای سریع)، تأخیر ناشی از ارسال دادهها به فضای ابری و بازگشت فرمان، قابل قبول نیست. استراتژی باید شامل اجرای بخشی از پردازش و مدل AI بر روی سختافزارهای نزدیک به سنسورها (Edge Devices) باشد تا تصمیمگیریها به صورت Real-time و با کمترین تأخیر انجام شوند
-
.
-
اتصال به سیستمهای عملیاتی (Legacy Systems): بزرگترین چالش، اتصال مدلهای مدرن AI به سیستمهای کنترل صنعتی قدیمی (DCS یا SCADA) است. این امر نیازمند استفاده از میانافزارهای (Middleware) تخصصی و تیمهای IT با تجربه بالا است.
ب. پایش، بازآموزی و خلق ارزش
-
مانیتورینگ فرسایش مدل (Model Drift): مهمترین وظیفه پس از استقرار، پایش مداوم است. به دلیل تغییر تأمینکنندگان مواد اولیه، فرسایش سنسورها یا تغییر شرایط محیطی، دقت مدل به مرور زمان کاهش مییابد (Model Drift). سیستم MLOps باید به طور خودکار این افت دقت را تشخیص دهد و در صورت لزوم، فرآیند بازآموزی (Retraining) مدل با دادههای جدید را آغاز کند. بدون این حلقه بازخورد خودکار، مدل پس از چند ماه از کار میافتد.
-
خلق ارزش جدید با زیرساخت: زیرساختهای جمعآوری داده که در فاز ۲ نصب شدند، اکنون به کانال انتقال ارزش تبدیل میشوند. با استفاده از این بستر، شرکتهای سازنده تجهیزات میتوانند:
-
خدمات نگهداری پیشبینانه (Predictive Maintenance) را به مشتریان بفروشند (ارزشافزوده سمت راست منحنی).
-
تشخیص عیوب از راه دور را فراهم کرده و تیم خدمات را قبل از بروز خرابی بزرگ، به محل اعزام کند.
-
این حلقه، دادههای خدمات انجام شده را نیز برای بازآموزی مدل (MLOps) باز میگرداند و چرخه عمر مداوم AI را تکمیل میکند.
-
-
استراتژی مقیاسدهی (Scaling Strategy): پس از موفقیت کامل در یک واحد پایلوت، استراتژی باید شامل یک نقشه راه مشخص برای تکرار و مقیاسدهی سریع آن راهحل به سایر خطوط تولید یا سایتهای جهانی شرکت باشد.
نتیجهگیری: پروژههای هوش مصنوعی صنعتی نه به دلیل کمبود هوش، بلکه به دلیل کمبود استراتژی یکپارچه شکست میخورند. مدیران امروز باید درک کنند که AI، نیازمند یک رویکرد بالا به پایین (Top-Down) است که از همسوسازی استراتژیک شروع شده، با زیرساخت دادهی قوی و پلتفرمهای ارتباطی امن تقویت گشته و با پرورش متخصصان داخلی و یک سیستم MLOps پایدار و خودکار به پایان میرسد. این تنها راه برای فرار از آمار ۹۰٪ شکست و ساخت یک AI پایدار است.






دیدگاه خود را بنویسید